在之前文章聊聊JMM,说到了内存屏障,内存屏障在Java语言实现一致性内存模型上起到了重要的作用,本文我们一起聊一聊内存屏障
内存屏障是什么
在cpu执行指令的过程中,对于同一个线程中没有数据依赖的指令可以重新排序优化,有数据依赖的指令按照顺序串行执行,来保证单线程程序运行的正确性,同时也提升了CPU的执行效率,合理的利用了CPU等待时间,
在多核CPU的情况下,因为多核CPU上的指令同时执行,如果涉及到共享变量的修改,这种优化会影响多线程运行的正确性,而内存屏障(memory barrier/memory fence)是硬件层面提供的一系列特殊指令,当CPU处理到这些指定时,会做一些特殊的处理,可以使处理器内的内存状态对其它处理器可见,在不同的平台上支持的内存屏障也会有差异。
解答之前的疑问
在之间的文章聊聊缓存一致性协议中,结尾提到一个问题:MESI频繁的消息请求与响应带来的性能问题如何解决?
MESI协议解决了缓存一致性问题,但是频繁的请求与响应,会产生大量的等待时间,请求等待响应的返回之后才能将数据写入高速缓存中,为了避免减少这种性能问题,硬件层面引入了写缓存(store/write buffer)和无效化队列(invalidate queue), 结构如下图
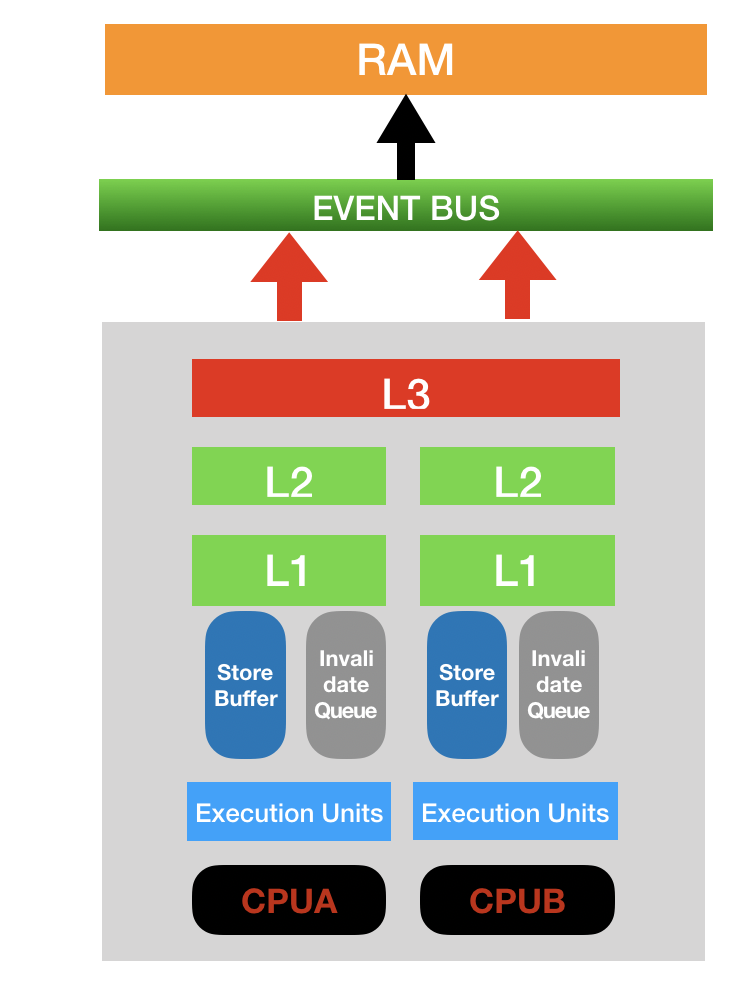
写缓冲器(store buffer也称为 write buffer)是处理器内部的一个容量比高速缓存还小的私有高速缓存部件,每个处理器都有自己的写缓冲器,写缓冲器内部包含若干个条目,并且写缓冲器之间是无法直接访问的。引入写缓冲器,使得处理器在执行写操作的时候,写入写缓冲器中,而不需要等待response响应,来减少写操作的延时,在节省的时间内可以执行更多其它指令,从而提高处理器的执行效率。
无效化队列是用处理Invalidate消息的,当该消息被广播到总线上,其它的CPU都在监听此消息,同其它的CPU都要回复一个Invalidate Response消息,这会产生大量的广播事件,所以在引入无效化队列之后,处理器在收到Invalidate消息之后,并不立马删除地址中对应的副本数据(其实是更新缓存行的状态为无效),而是将消息存入无效化队列之后就直接响应Invalidate Response消息了,从而减少了写操作执行处理器的等待时间。
通过写缓冲器和无效化队列的,将消息累积起来,立马响应请求,提高处理器执行效率,然后在特定的时间(写缓冲满之后或者执行到内存屏障 ),批量将写缓冲中的数据写回主存,将无效化队列应用到高速缓存中,但是他们的引入,又带来了内存重排序和可见性问题。
写缓冲器和无效化队列带来的问题
写缓冲器导致StoreLoad重排
写缓冲器导致StoreStore重排
无效化队列导致LoadLoad重排
CPU对共享变量的更新,到达写缓冲器中就返回了,这就可能导致其它CPU无法读到共享变量的最新值,因为共享变量的修改还在前一个CPU的写缓冲器中,连高速缓存都没到了, 无法通过MESI协议保证一致性,这个现象就是可见性问题
CPU对于Invalidate的请求,到达无效化队列之后就返回了,还没有将高速缓存中的相关副本数据删除,这就可能导致该处理器读了的数据是过时的数据 ,从而导致更新丢失 ,这个现象也可以理解为是可见性问题
对于上面的问题,用到的就是我们今天的主角,内存屏障
内存屏障分类与作用
在X86平台提供了几种主要的内存屏障
- lfence - 加载屏障
- 清空无效化队列,根据无效化队列中内容的内存地址,将相应处理器上高速缓存中的缓存条件状态置为I,使后续对该地址的读取时,必须发送Read消息,具体过程可参考 聊聊缓存一致性协议
- 用在读指令前,阻止屏障两边的读指令重排
- sfence - 存储屏障:
- 冲刷写缓冲器中的内容,将写缓冲器中内容的更新应用于高速缓存
- 用在写指令之后,阻止屏障两边的写指令重排(执行到该屏障时,将对缓存中的条目打标记,标识这些条目需要在该屏障之前提交,当执行到写操作时,检测到写缓冲器中存在被标记的条目,不管写操作对应的条目状态,即使是E,M也不将写操作的数据回写高速缓存,而是写入写缓冲器的方式,使得屏障之间和屏障之后的指令修改都串行在写缓冲器中,来保证其顺序)
- mfence - 全能屏障
- 具备ifence和sfence的能力, 实现是通过加载屏障和存储屏障的成对使用,可以保证写缓冲的内容同步到高速缓存,无效化队列的内容应用到高速缓存,然后再根据缓存一致性协议保证共享数据的一致性
- 阻止指令重排
结束
下一篇可能会写一篇java中使用内存屏障实现的语义
